ARCHER 3.2
Distribution of work
Some text from versions 1 and 2 which had to be excluded from version 3.1 have now been restored, and consortium members have contributed new texts to help fill remaining gaps in coverage in national varieties, genres and periods. Team locations specify where the bulk of the work was carried out, even if members have since moved.
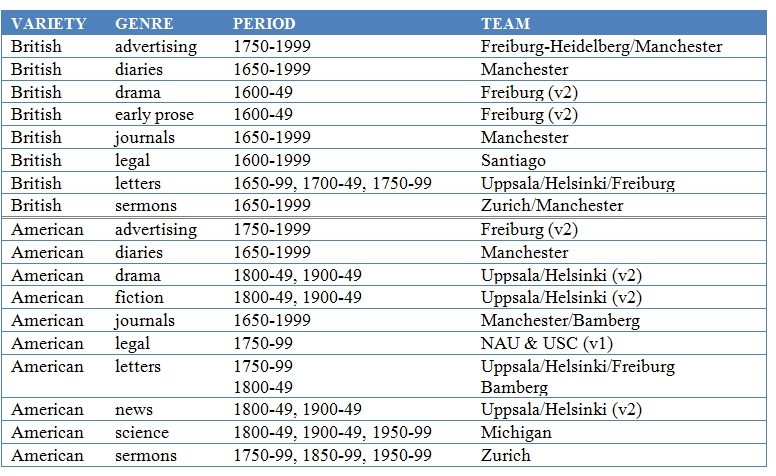
Image 6. Contribution
There are some natural limitations to material available in some genres in early periods, but two gaps in American coverage should be filled in version 3.3, as shown:
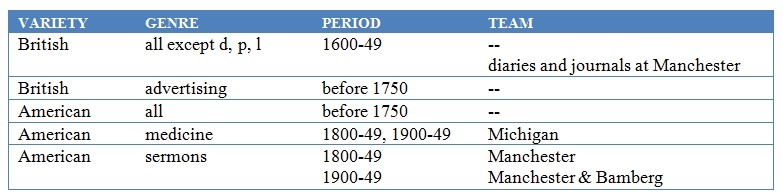
Image 7. Genres
The following consortium teams have made further contributions:
- Freiburg: VARDing
- Lancaster: VARDing, POS-tagging, CQPweb
- Leicester: POS-tagging
- Manchester: database management; documentation; text revision and annotation; design of TEI‑headers
- Trier: word count and word list scripts
- Zurich: XML-compliant format in text and headers; consistency of mark-up; tagged and parsed version
The ARCHER team would also like to gratefully acknowledge the contribution of former research members: Marianne Hundt (Zurich, until November 2013), Arja Nurmi (Helsinki, until July 2012), Anna Rosen (Bamberg, until October 2011), Richard W. Bailey (Michigan, †2011), Chris Palmer (Michigan, until 2010). We are also very grateful to various research assistants at the consortium departments: Ole Schützler at Bamberg; Michael Percillier at Freiburg; Tuula Chezek at Helsinki; Lauri Hiltunen and Marije van Hattum at Manchester; Taryn Hakala at Michigan; assistants in the VLCG research group at Santiago de Compostela under the coordination of Paula Rodríguez-Puente; Moira Kindlimann and Pius Meyer at Zurich; Melanie Röthlisberger at Manchester and Zurich.
Formats
ARCHER 3.2 exists in four different versions to suit different users and uses:
- untagged plain text (extension .txt)
- non-POS-tagged XML version (extension .xml)
- non-POS-tagged files prepared and indexed for CQPweb
The master-copy of the ARCHER corpus is now fully XML-compliant and with TEI-compliant headers. In addition to XML (UTF-8 character set) and plain text (Latin-1), there will soon be a version part-of-speech tagged with the CLAWS-6 tagset. An additional online version (tagged with the Penn Treebank tagset, chunked, and dependency-parsed, Zurich) is expected to follow shortly, too.
The untagged plain texts can be consulted over the internet with limited context in CQPweb. The full text can be consulted at the consortium departments and can be opened and read with any text editor or concordance program. The non-POS-tagged XML can also be opened with any text editor but is more conveniently read in an XML viewer with a suitable style sheet (CSS). Such a CSS is available for download from the Documentation page on the project website.
ARCHER is essentially an original-spelling corpus, albeit the spelling of published editions. All versions share the same text and bibliographic and non-linguistic mark-up, but future online versions at Lancaster and at Zurich will differ in their linguistic mark-up.
ARCHER 3.2 CQPweb (Lancaster)
[coming soon]
ARCHER 3.2 (Zurich)
[coming soon]
|
